Semantic AI and Finding Understanding
One of our customers asked for the possibility to compare internally created documents as well as those sent by third parties against internal legal guidelines, standardized text clauses, historically created contracts, governance, and internal policies. All with the goal to give their specialists quick feedback on whether or not a certain passage, text or sentence is in line with what the experts would advice AND to be compliant with internal and external regulations.
To top it all off, they asked that documents that are being sent around during negotiations can be compared against various iterations of itself.
So, from a user requirement perspective the ask was clear:
- Get feedback on how a text compares to internal guidelines
- Understand what differences and/or similarities there are in semantic meaning
- See what is exactly matching or different
Track changes is not a solution, DIFF neither, and simple text comparison neither as they all depend on the exact same formatting for comparisons. Code looks at pixels or code, not at letters, and certainly does not analyze change the way a human does do. Microsoft solves this by the power of just having everyone use Word, other providers in the market (such as Tiny or CKE) do it by tracking literal pixel changes and clicks meaning, change, and/or comparisons can only be made if you are using 1 and the same program.
However, even if they could compare properly also from outside sources they all suffer another problem: they can only compare one source document against one other element. None of them can compare a single document against well … hundreds of other elements, let alone elements from different sources (think: PDF, word, online editors, etc.).
So let’s talk about semantic comparisons and AI.
Language Models and Understanding
The simple answer is of course, let’s use our AI model to solve this issue. On the face of it, it seems like a simple issue to tackle.Compare a single document (i.e. after cleaning it from all style elements a string of text) against various other sources in our platform.
Let’s deconstruct legal guidelines first. These are blocks of text with explanations and alternative wordings to those blocks of text. So, a base text with meaning and a description and an instruction to use alternative text if that base text does not suffice for the use-case. There’s meaning and reference both. Not something that we cannot train our AI to understand so we set off.
We cleaned the document and its style elements, setup the pipeline, took the strings of text that were leftover and compared all aforementioned text-blocks against it. For every text-block (legal clause) a separate semantic comparison: document x text-block; document x text-block; document x text-block and so forth. In our test-case: 142 text-blocks and therefore 142 operations.
Before we continue with the analysis, it’s important to understand that with semantic comparisons you are going to find similar meaning – not the same text. Keep that in mind as it depends on what you want to achieve and, what technologies need to be applied.
How semantic comparisons work, in short
Comparing two documents and highlighting either differences or similarities works roughly the same. Take an open-source AI model (or your own one like we did), and consider leveraging a combination of Natural Language Processing (NLP) techniques for semantic analysis and difference detection.
It all starts, like almost anything you want to do with NLP, with text pre-processing. You clean both sources (e.g. convert to lowercasing, remove punctuation/special characters, etc.), tokenize & encode the tokens into numerical representations using your chosen model (this ensures that the model can process the tokens).
Next you use semantic comparison to create vectors that can be checked for similarity or difference. The vectors will be given a similarity score (we recommend using cosine similarity but there are numerous other options such as Euclidean distance or dot product similarity). We prefer cosine similarity and recommend it because it measures the cosine of the angle between two vectors, indicating the similarity of the direction in the vector space.
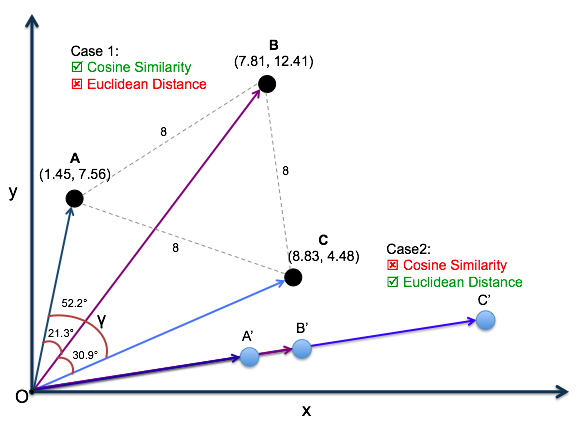
Case2: the rare case when Euclidean distance is better than Cosine similarity
Image credit: Vijaya Sasidhar Nagella
Make sure you set a threshold meaning, what constitutes enough similarity (or difference) for you to pick up on? With cosine similarity, this obviously is any number between -1 and 1. 1 being 100% ‘same’. Using a lot of experimentation and feedback on the actual use case you are working on (or giving the users the possibility to set values but from our experience …. best to avoid that for now) you will be able to find a good threshold.
Next, highlight either similarities or differences. For each pair of text chunks, compare their similarity score against the threshold. If the similarity score exceeds the threshold, consider the text chunks to be similar and highlight them accordingly. You can use HTML/CSS to visually highlight the similar portions of text, such as changing the background colour or adding a border around the text. You can use traditional diff algorithms or a specialized library like difflib in Python for this.
And VOILA results ….
Right?
The map is not the reality
So in theory it is that easy. But, get to a real-world use-case and you run into a lot of problems. For one, we have now compared a full document against another piece of text. If you compare two ‘comparable’ documents that is fine. But if you want to understand the implications of legal guidelines, policy documents or even just find a single standardized clause in a document it is not that easy anymore. The user does not want to have to repeat the process each time for each individual document, source, policy or guideline he/she wants to understand against the document he/she is working with.
Also, indiscriminately running a semantic comparison against ALL source materials you have works if you have 20 documents but not if you, like our customer, have thousands of simultaneous users, hundreds of documents and tens of thousands of source materials to compare it to in the future. And, not to forget, a user wants to see the information (i.e. the output) in a single screen and not have to click through thousands of comparisons.
If you were carefully reading the last chapter you will have recognized that with the previous method you take a full document, convert it to a single vector and compare that vector against another single vector. Resulting in 1 single similarity score. Meaning: document y is for x% similar to source material z. Every time you repeat the process, you get a similarity score of ENTIRE document against ENTIRE comparison. If there 1000 elements you are comparing it against, you will have 1000 outputs and a corresponding 1000 visuals. Our users want these 1000 outputs converted into 1 visual. Which … is not possible with the method just described.
Visual problems, hardware limitations, user impatience & mathematical solutions
So now we have a method but not the desired result. In order to solve problems, we need to name them first.
- Visual output
Which, when solved creates another problem:
- Processing time
1 vs. many comparisons – visual problems
Our method gave the user a visual output where similarities or differences were highlighted. In theory a good result but if the user is comparing one source document against thousands of other sources he/she’d have to click through thousands of visual comparisons. Not exactly user friendly.

Example of a 1 vs 1 comparison, now imagine the left staying the same but the right having 1000 different results and having to click through that.
To solve this problem we chopped up the source document and the other sources (i.e. the text-blocks, policies, governance, contracts, regulations etc.) into single sentences. In short: comparable vectors. Now, all we needed to do was to compare all vectors from a source document against ALL other vectors to create a single visual output or let the user quickly switch through categories. Meaning: compare sentence 1 of the document against sentence 1 of our comparison material, sentence 2 of your document against sentence 1 of your comparison material and so forth.

Imagine the image above, the first sentence however connecting to every line on the right and then repeated for every line below that.
Want to see what our policies say about this document? Want to see how it compares against our legal guidelines?
Our solution worked. Except…
If you have a document with 500 sentences (which is not a lot, trust us) and you want to compare it against just a single other sentence you already need to run 500 calculations. If you now compare it against hundreds of thousands of sentences (because that is how many you will have if you have a body of knowledge in a company) you are looking at millions of calculations.
To exemplify: comparing a document with 1500 sentences against 155 company internal legal clauses with a total of 4700 sentences cost us 3 hours and 22 minutes on a very high end GPU. That’s 9,- EUR of hard earned money and a whole lot of time for a user to wait for results.
Leading to problem number 2.
1 vs. many comparisons – processing time
In our tests, even with an optimized pipeline, data extraction, tokenization and model analysis, comparing a single document of 24 pages against another document of equal length took approximately 14 seconds on the highest end graphics card (note: this includes everything). That’s 14 seconds the user would have between sending the request and seeing the result.
That is 1 user request for 1 document comparison against a single other document. Neither of which are very lengthy.
Take it up one notch and you’ll land at the example we gave above where the processing time was well over 3 hours.
So how to solve this? Throwing more hardware at the problem is not going to work, not only is it commercial suicide but we’d never get close to an acceptable time that a user would have to wait for his/her output.
We’re going to have to draw. But fist, let’s properly describe the situation before we start drawing.
Situation
I am a user and I just received a document from a third party. I want to see how the wording in the document compares to my legal guidelines if there are problems with our internal policies and what my legal department suggests as alternative wording so that I can negotiate with my counterparty more efficiently and without delay whilst having to wait for an answer from the internal experts. OR I am a user and am writing a document and want to see what my legal, compliance, and risk colleagues have to ‘say’ about my written text by quickly comparing it and getting suggestions from the model on how to adjust.
Analysis
We have now identified a number of categories of source materials against which a document is to be compared namely:
- Legal Guidelines
- Standard (text) clauses and their alternatives
- Internal Policies
- A body of historical documents that are written for similar situations
Theoretically you can expand this list indefinitely but let’s work with this for the example.
4 categories with in each of these categories a potentially unlimited number of documents. Each document a varying number of sentences.
The first step to solve the problem is easy – the old switcheroo. Don’t compare the document against these sources, do it the other way around. This let’s us pre-filter and thereby limit the number of comparisons we need to make.
The second step is also easy – let the user indicate what he’d like to get advice from: is it historical data? Legal guidelines? Or any of the other categories? Usually, there is no need to try to put everything in a single overview, this would only overwhelm the user anyway. Let’s hypothetically say that each of the categories has an equal number of documents with an equal number of sentences (we’ll get to a real example in a minute). This now let’s us cut the processing time by 75% already.
The third step is more complex, but not rocket science either. Here is how it goes: take the first sentence of the first element (for instance a document or a text-block or a legal clause) that you want to ensure that is either in the document OR NOT. Compare that sentence against ALL sentences in the document (remember: vectors). IF you score one or multiple hits of (for instance) above 90% cosine similarity, mark that sentence (vector). Now take the second sentence of the same element and now ONLY compare it against 3 sentences ABOVE the marked sentences in the document and against 8 sentences BELOW. IF you score a hit of above 90% cosine similarity, mark it. Now jump to the last sentence of the element you are trying to compare and do the same as the last step but this time take 3 sentences above the first marked hit and x + 10 sentences BELOW the second hit. Where x is the number of sentences you skipped in the element. Score a hit? Voila, you can now extract the range of the text from the document, mark it fully and pull it up for a DIFF. More importantly, you can mark that passage as ‘1’ and skip it for the next element.

An overly simplified repeating flow diagram to show the steps.
With this method not only will you reduce the number of comparisons you need to make in your source materials but also in the document itself, gradually marking it down.
The map starts to look like reality

An image of some colorful lines. Jokes aside: the left represents two theoretical legal clauses and the right the full document. On the right, there is a marked section that represents a similarly scored passage.
So, what does this mean in real-life performance? Let’s put some real numbers on the table.
Enhance…
Enhance…
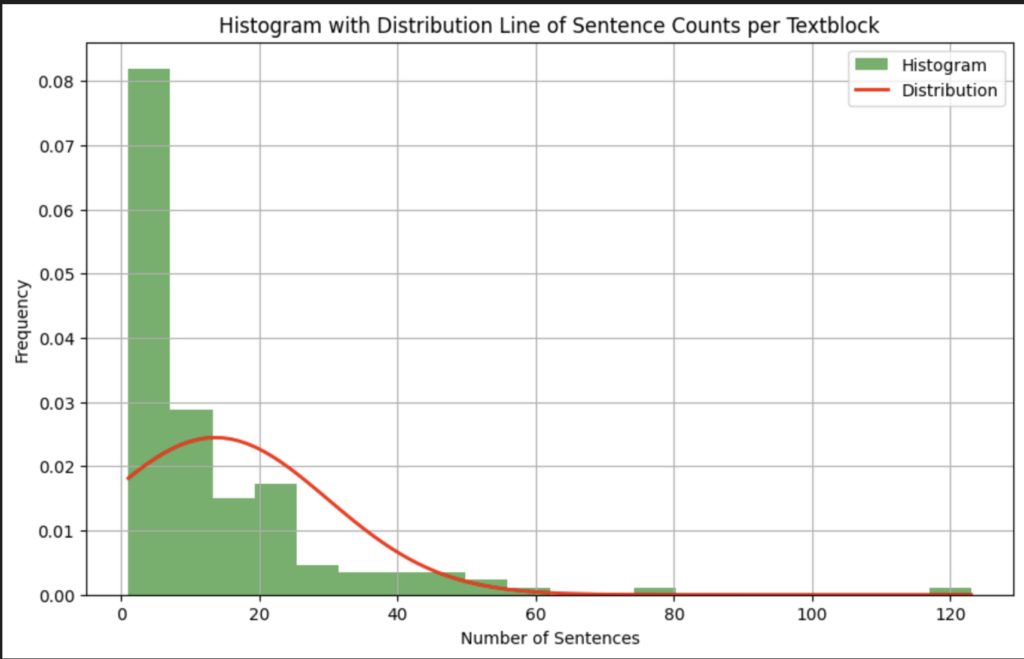
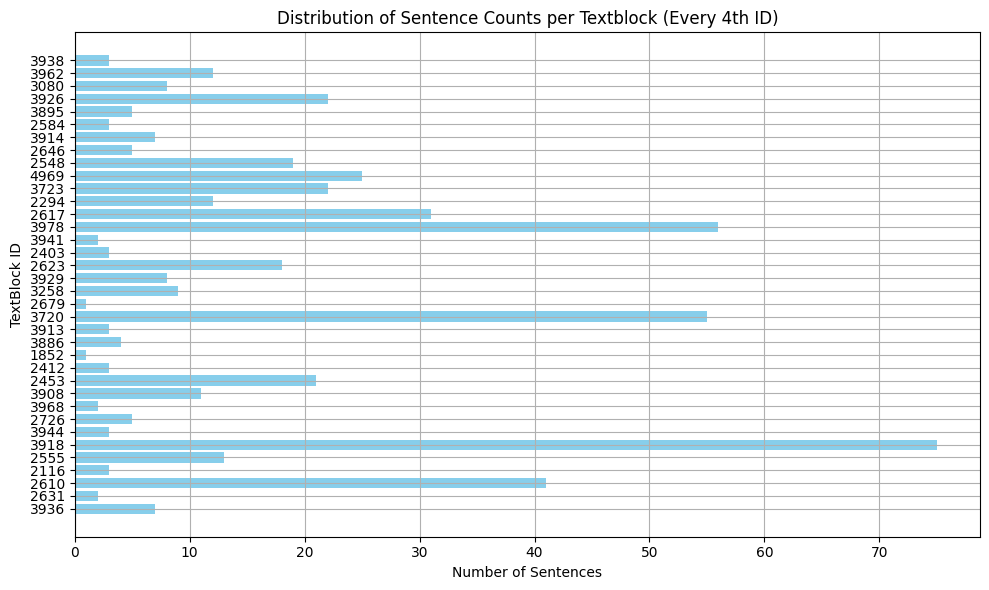
Our test document has 1097 sentences. We compared 142 number of ‘legal clauses’ with a total of 1932 sentences against it to check for semantic matches. If we would not optimize this, it would be a total of 2.119.404 calculations.
The average number of sentences per legal clause was 13,6. However, averages do not tell the story. If we plot the clauses to group the text blocks with the same number of sentences together we start to see a good picture. There was 1 legal clause with 142 sentences, this is an outlier, however. There are 9 legal clauses with 40 or more sentences, 22 legal clauses with 20 to 39 sentences, and 30 legal clauses between 10 and 20 sentences. The bulk, namely 80 legal clauses has 10 or fewer sentences. Out of these 80, 36 had 3 or fewer sentences. So for approximately 25% of the elements, our optimization did not apply.
Now, if we want to calculate the optimization we have achieved in this realistic (we scrambled data from a real customer) scenario we need to look at how many sentences we do not have to semantically match and instead can compare with the not compute intensive DIFF function. However, before continuing we must answer the question about accuracy. How accurate were the results of our optimized method vs. comparing each vector separately against each other.
The answer is 1 – we got exactly the same results, even after reducing even further.
So what we now have are the following parameters:
- Take the first sentence of the first element you’d like to compare against the source document and scan for (a) match(es)
- If 90% or higher, mark it
- Take the second sentence of the same element and scan for the match(es) 3 sentences above and 5 below the match(es) of step 1
- IF 90% or higher, mark it AND
- Skip to the last sentence of the first element. Count the number of sentences between the second and last sentence of the mentioned element, add 5 to it, and search that number below the last marked sentence in the source document.
- IF 90% or higher, mark it AND
- Mark all vectors between the 1st and last in the source document, and export these vectors so they can be used in DIFF
The savings are the sentences in between plus the reduced text in the source document. Since we cannot account for Hit Rate in the source document in our calculations we leave that out of our optimization. What is left is the following (based on our example above):
The original time to embed and semantically match the test case above (2.119.404) was 2 hours and 20 minutes on a single very high-end GPU. (Total cost: 5.60 EUR per matched document)
Using our improvements we reduced it to under 2 minutes, an improvement of 98,57%. This also means we are now at <0,97KJs of energy use per request translating to (including cost of hardware, and maintenance) 8,1 cents per request.
Now, even though this is a great result we are not yet satisfied. Why not? 2 minutes is too long for a regular user to have to wait for a result. We’ll be working on improvements in the coming weeks to see how we can further optimize and post those in another post. Stay tuned!
TLDR;
Not interested in how we solve things but interested in the results? The short version is this: we were able as one of the first (maybe even the first and only but I am too lazy to research) to allow our users to get near-instant feedback on ANY type of document that they are working on against the entire body of knowledge of a company or even the market. Starting in May, we are going live with the option for companies to let users get feedback on their or counterparties’ documents by comparing them against legal guidelines, policies, external regulations, and lots more.
Not the imaginative type? Let me give some examples:
- Compare a contract you are working on against the legal guidelines your legal department has set
- Compare a contract against internal policies
- Compare a customer contract against regulatory requirements
- Compare a supplier contract against the CSDDD
- Automatically check compliance with specific regulations or internal policies
- And pretty much anything you would like to get compared or get feedback on
Contact us if you have questions about how to solve this yourself or if you’d like to try us out or …. you’d just like to have a chat.
Reach out on LinkedIn: https://www.linkedin.com/company/contractuo
Or X (Twitter): https://twitter.com/contractuo
Or write an email: [email protected]